I have the same problem, and yeah, that's the site. Tapping the button to increase the font size just zooms the page in so now I have to scroll horizontally to read the content. Something on the page is preventing natural reflowing, I could probably figure out what if I was on my desktop. My hunch is it's the row of images.
Haven't got the chance to play around with it, but looks fun. And maybe something cool to use to repackage into an alternative Tor/I2P browser for hidden websites.
What's holding back CSS and HTML support (at their specific versions) and is there interest of expanding that support in full, but lacking resources?
- It is extremely slow and resource intensive. Opening any link/page takes at least 3 seconds on my fastest computer, but the content is mostly text with images.
- It cannot be used without JS (it used to be at least readable, now only the issue description loads). I want the bug tracker to be readable from Dillo itself. There are several CLI options but those are no better than just storing the issues as files and using my editor.
- It forces users to create an account to interact and it doesn't interoperate with other forges. It is a walled garden owned by a for-profit corporation.
- You need an Internet connection to use it and a good one. Loading the main page of the dillo repo requires 3 MiB of traffic (compressed) This is more than twice the size of a release of Dillo (we use a floppy disk as limit). Loading our index of all opened issues downloads 7.6 KiB (compressed).
- Replying by email mangles the content (there is no Markdown?).
- I cannot add (built-in) dependencies across issues.
I'll probably write some post with more details when we finally consider the migration complete.
It's an excellent choice. Though Microsoft alone should be a sufficient answer. Many people will never interact with github projects because it requires an account with the most unethical company that ever existed.
There's companies out there whose main source of business is wetworks, as in drone strikes and so on, microsoft going for the most unethical title, I don't think its even in the ranking.
I do agree that not using it is better morally, however, given the limitations of git vs fossil, which carries the issues and wiki inside the repo itself, its not a good idea to switch to another service without guarantees that its host will be forever standing, github won't die in the next decade, but the alternatives mentioned might. even google (code) got out of the source hosting business.
But your confidence in GitHub's continued existence comes from its network
effects, no? And competing services can only gain such network effects if
more people use them. So to me this feels like a defeatist argument.
This is not a magical achievement, github is solvent and its business model is solid, give the same amount of users to any other service and it might collapse. Any service has to scale and the more users it has the more costs it incurs, nonprofits are a risk, the moment they run out of money, the service collapses.
If it's not a magical achievement, then surely competitors could replicate
it too.
Of course you can't put a million users today in a service used by a
thousand yesterday, but I don't buy the "non-profits don't scale" argument.
If that were true, we wouldn't have Wikipedia either.
Replication is not enough, Competition only wins if it offers lower cost or better service (or intolerable service if free), While yes, the userbase is essential, you're still ignoring the reason why the userbase is there in the first place services before github existed and github is the one that ended up winning, competition cannot just offer a better ethical stance and its not even that, since github itself is not doing anything criminal, it's simply aligned with microsoft, so the ethical stance is "I don't like AI" and "I don't like microsoft", that is simply not enough of an offer to make the entire userbase switch. the only way you could is if github decided to throw all of its userbase like bitbucket did, and given that its name is git, I doubt they'll ever do that.
To clarify, I think it's fair to say "I use GitHub because I don't think MS is that bad" (I disagree, but it's at least a consistent view.)
I only take an issue with "I think MS is morally reprehensible but everybody uses it so I'll keep using it too" because it's a self-fulfilling prophecy. Most people looking for code hosting will use whatever they first run into, so when you choose a host for your project you are also directly channeling users towards said host. It's your responsibility to pick a host for your projects that isn't evil by your standards, whatever those may be.
Not even in the tech world. Microsoft did more than its fair share of cutthroat business practices, but there are tech companies out there that are quite literally thriving on worker exploitation.
Belgian Congolese tire companies under King Leopold, Atlantic slave trade companies, Basil Zaharoff and Vickers who sold machine guns to both sides agitating WW1, IG Farben who did the Nazi gas chambers, Shell oil who since the 1970s continues spending billions funding climate change disinformation and billions preparing for it, at the same time... It's a long list.
Take Hyundai, a brand I drive, childhood slave factories, in the 2020s... You can't even brush your teeth without the ghosts of slavery.
Reasons 1, 2, and 4 convince me the most. It's insane how slow and cumbersome github's code review page has been is ever since they moved from rails to react.
I remember installing Debian on my OLPC XO-1. Dillo and Netsurf were the only browsers that I even tried running on that thing (w. 512MB RAM). Netsurf had better compatibility, but Dillo was noticeably faster and more responsive. Truly a pleasure to use when it supported the site I was on.
I think it is becoming more important to i386 BSD, especially since i386 OpenBSD can no longer build Firefox, Seamonkey and IIRC Chrome on i386 systems.
I have been using dillo more and more as time goes on, plus you can get plugins for Gemini Protocol and Gopher.
gemini://gemi.dev with News Waffle it's a godsend to read bloated news sites, both in English and in Spanish. Also, gopher://magical.fish The register, some bloated Spanish such as Xataka and Genbeta...
Hi there - love Dillo. I use it on NetBSD and it works great. Once you're off GitHub will there be a way to get notified of releases? I use GitHub's RSS feeds for that now.
It fetches the issues from GitHub and stores them in <number>/index.md in Markdown format, with some special headers. I then keep the issues in a git repository:
So we have a very robust storage that we can move around and also allows me to work offline. When I want to push changes, I just push them via git, then buggy(1) runs in the server via a web hook. This also tracks the edit changes.
While typing, I often use `find . -name '*.md' | entr make` which regenerates the issues that have changed into HTML as well as the index, then sends a SIGUSR1 to dillo, which reloads the issue page.
The nice thing of allowing arbitrary HTML inline is that I can write the reproducers in the issue itself:
If you're looking for something light, self-hostable and a bit more "social" (i.e. with pull requests and bug creation from the web) I recommend looking at https://tangled.org It doesn't render perfectly in Dillo but basic features appear to work.
However I really like what you've done here for Dillo as well.
Yes, but all those services have the same main problem: a single point of failure. They also don't work offline.
I believe that storing the issues in plain text in git repositories synced across several git servers is more robust and future-proof, but time will tell.
Having a simple storage format allows me to later on export it to any other service if I change my mind.
> Uses the fast and bloat-free FLTK GUI library [1]
Bloat as a moat, is sadly the strategy of much of the web or apps in recent years. High Performance has shifted into how fast we can serve bloat. Efficiency has become about pushing the most bloat with least time.
Pages are bloated, sites are bloated, browsers are bloated, browser-market is bloated (two-a-dime! or three for free). The whole damn web is a big bloat. wtf happened.
"High performance has shifted into how fast we can serve bloat."
If remove ads and behavioural tracking, speed is faster
But goal of Big Tech, who make the popular browsers, is to make speed faster (fast enough) _with_ ads and tracking
User wants fast speed. User does not want ads and tracking. Big Tech wants users in order to target with ads and tracking. Big Tech tries top deliver fast speed to keep users interested
User can achieve fast speed _without_ ads and tracking
I do it every day. I do not use a large propular browser to make HTTP requests nor to read HTML
Probably the best indicator of which features are supported is to pass as many tests as possible from WPT that cover that feature.
I did some experiments to pass some tests from WPT, but many of them require JS to perform the check (I was also reading how you do it in blitz). It would probably be the best way forward, so it indicates what is actually supported.
> but many of them require JS to perform the check
Yeah, if we add JS support to Blitz then one of our initial targets will probably be "enough to run the WPT test runner".
> I was also reading how you do it in blitz
We are able to run ~20k tests (~30k subtests) from the `css` directory without JS which is IMO more than enough for it to be worthwhile.
> Probably the best indicator of which features are supported is to pass as many tests as possible from WPT that cover that feature.
Yes, and no. It definitely is an indicator to some extent. But in implementing floats recently I've a lot of the web suddenly renders correctly, but I'm only passing ~100 more tests!
Yeah, but C++ compilers are pretty heavyweight. That said, rewriting a C++ codebase in C is about as likely as rewriting it in Java, so it wasn't a good suggestions.
I just compiled some C++ code using G++ under ulimit -v 108032, but it didn't use much of the STL. For a simple example program using iostream, vector, unique_ptr, and std::string, I needed more, but had success with ulimit -v 262144: http://canonical.org/~kragen/sw/dev3/docentes.cc.
I'm not sure how much RAM you need to compile G++ itself. More, I imagine. I was definitely compiling versions of GCC long before I ever saw a machine with so much RAM as 1GB, but I am guessing you probably need at least 1GiB for recent versions, maybe 4GiB.
LLVM, which is required for both clang and Rust, is much heavier. You definitely can't compile current versions of LLVM on i386, m68k, or any 32-bit platform anymore. You can get it to cross-compile to them as targets. In theory there are PPC64 machines that have enough address space to build it, but I'm not sure anyone ever made a PPC64 machine with enough physical RAM to build it in a practical span of time.
I run OpenBSD 7.8 under an i386 ATOM netbook, n270 CPU and 1GB of RAM.
I hav no Rust, but I have C++, JimTCL, nim (I compled Chawan). Go runs, too.
Maybe I can't compile LLVM in my netbook, but a tuned up machine with 2-4GB of RAM might be able to do such task with a bit of swap in a SSD and boosted up login.conf limits.
Maybe so, but I think it would have to be an amd64 CPU rather than an i386. Maybe you could do it inside of QEMU; does QEMU running on i386 permit emulating address spaces larger than 4GiB?
If you want to compile a recent c++ compiler (gcc/clang), you must have already a c++ compiler (one of the biggest mistake in open source software ever was to move gcc to c++, clang doing the wrong thing right from the start...).
You can start to compile gcc 4.7.4, the last gcc compiler with buggy c++98 you could compile with a C compiler (you will need to patch it, and even unroll its full SDK), then you will have to compile at least 2 gccs to reach the last gcc. This insane mess is due to the infinite versions of c++ ISO "standard", introducing tons of feature creep which will force you to "upgrade" (mostly no real good reasons, namely developer tantrums, or planned obsolescence).
This is disgusting, Big Tech grade abomination of software engineering, shame on the people who did that and those in power who are not trying to fix it (probably the GCC steering committee).
Rust it's worse for that; for full reproducibility you almost need to create a release-centipede from an old GCC-rs (or GCC) compilable release to the current one. At least that's the norm under Guix.
On cproc, cparser, I meant that we have no lightweight c++ compilers and sadly the closest to cparser in lightness it's clang++, because it's either that or the g++ behemoth.
In the light of all that, there are still people unable to understand why computer languages with ultra-complex syntaxes are really an issue (c++, microsoft rust, etc...)
More like complex, overloaded. ML languages have a complex syntax but are manageable.
OTOH, on Lisp, about bloated languages like Common Lisp compared to Scheme, you don't have to follow all the Common Lisp Hyperspec in order to create something; a subset would be pretty fine, even without CLOS. Scheme IMHO it's worse with SRFI's with tons of opaque numbers in order to guess what does that. And don't let me start on Guile modules vs the Chicken ones...
People rants about CL being a bit 'huge', but with the introduction to the Symbolic Computation book and Paradigms of Artificial Intelligence Programming you are almost done except for a few modules from QuickLisp (CL's CPAN/PIP), such as bordeaux-threads, usockets and MCClim for an UI, which will run everywhere.
C++ templates can be far more complex than Common Lisp macros. At least with CL you have a REPL to trivially debug and inspect then. Clang and GCC just recently began to introduce * understandable* help and error messages over template parsing walls...
If fltk had C bindings it would have been a thing long ago, because usually C programs will run faster than their C++ counterparts. DIllo's requeriments would be far smaller (and Dillo runs on potatos, I won't be surprised if it still runs on i486 machines)
If anyone is interested in a modern take on a lightweight, embeddable web browser / browser engine (that supports features like Flexbox, CSS Grid, CSS variables, media queries, etc), then I'm building one over at https://github.com/DioxusLabs/blitz
This month I have been working on support for CSS floats (https://developer.mozilla.org/en-US/docs/Web/CSS/Reference/P...) (not yet merged to main), which turn out to still be important for rendering much of the modern web including wikipedia, github, and (old) reddit.
EDIT: I should mention, in case anyone is interested in helping to build a browser engine, additional collaborators / contributors would very welcome!
Mentioning your usage of servo components might help with credibility. You're not starting from scratch.
Edit: to be clear, I consider this a good thing. You've got a head start, are contributing to the ecosystem and aren't doing by yourself something that others have spent billions on.
Yes, we've deliberately tried to make use of existing libraries (either from other browser engines or general purpose libraries) where possible.
The main thing we pull in from Servo (which is also shared with Firefox) is the Stylo CSS engine, which is a really fantastic piece of software (although underdocumented - a situtation I am trying to improve). I was recently able to add support for CSS transitions and animations to Blitz in ~2 days because Stylo supports most of the functionality out of the box.
(the other smaller thing we use from servo is html5ever: the html5/xhtml parser)
We also rely on large parts of the general Rust crate ecosystem: wgpu/vello for rendering (although we now have an abstraction and have added additional Skia and CPU backends), winit for windowing/input, reqwest/hyper/tokio for HTTP, icu4x for unicode, fontations/harfrust for low-level font operations, etc.
And while we're building the layout engine ourselves, we're building it as two independently usable libraries: Taffy for box-level layout (development mostly driven by Blitz but used by Zed and Bevy amongst others), and Parley for text/inline-level layout (a joint effort with the Linebender open source collective).
---
I wish that the Servo project of 2025 was interested in making more of their components available as independent libraries though. Almost all of the independently usable libraries were split out when it was still a Mozilla project. And efforts I have made to try and get Servo developers to collaborate on shared layout/text/font modules have been in vain.
Could this run in Wasm? Even if it was just running it 'headless'? I'm looking something like this to manage layout / animations of text like the DOM to plug into WebGL.
That's a bit of an open question at the moment. The obvious choice from a Rust ecosystem perspective (easiest to integrate) would be Boa (https://boajs.dev/). It has excellent standards conformance, but terrible performance. We'd need to test to what extent that would be an issue in practice.
Other engines on my radar: quickjs, hermes, primjs (and of course V8/JSC/SM, but they don't exactly fit with the "lightweight ethos").
There is also the possibility of bindings with more than one engine and/or using some kind of abstraction like NAPI or JSI.
Dillo is hands down the best ultra lightweight browser ever developed in my opinion. I had a Toshiba Tecra that I got from Goodwill when I had absolutely no money whatsoever in my college days, And it was at least 15 years out of date as a laptop even when I first got it. I installed Puppy Linux on it, and I had Dillo as the browser. Its ability to bring rapid web browsing to old hardware is without equal.
I still use a modern version of it now on a Pine Tab 2 tablet, which has slow enough hardware that you want something like Dillo to make it feel snappy. I just make sure to bookmark lightweight websites that are most agreeable to Dillo's strip down versions of web pages.
It's one of the reasons I feel like Linux on the desktop in the 00s and 2010s had the superpower of making ancient hardware nearly up to par with modern hardware or at least meaningfully closing the gap.
How does it compare with NetSurf? Whenever I'm setting up Linux, I usually start with NetSurf to download the other requirements. I'll have to give Dillo a look.
I consider Netsurf to be a beautiful and excellently well-done browser in its own right, so you can't go wrong with either.
But by comparison, Dillo is much more lightweight than even Netsurf (!!), much more brutalist, and a bit more idiosyncratic and the kind of texture and feel of how tabs behave, how you handle bookmarks, how you do searches. Dillo uses fltk while netsurf uses gtk3, and a lot of the resource usage savings in differences in vibe and feel come from that by itself. Netsurf is much more familiar if your baseline is standard modern browsers, and Netsurf does a better job of respecting CSS and rendering pages the way they should look.
Dillo can take a little bit of getting used to but it's a usable text oriented browser that I think is probably as good as it can possibly get in terms of minimalist use of resources, although at a rather significant compromise in not rendering many web pages accurately or using JavaScript or having an interface intuitive to the average person.
In 2007 it was moved to Mercurial which I then exported to git when the hg server went down. The history from 2002-2007 was lost (I believe SVN), if someone still has a copy please send it to us. See the missing section:
I used Dillo in 2001-2002 with the PlayStation 2 Linux kit. With 32MB of RAM for Linux, and 4MB for the graphics. It worked really well despite the CPU was 294MHz (MIPS R-5900, two-way in-order CPU, with SIMD unit, and only one hardware thread, having two auxiliary vector units as companions).
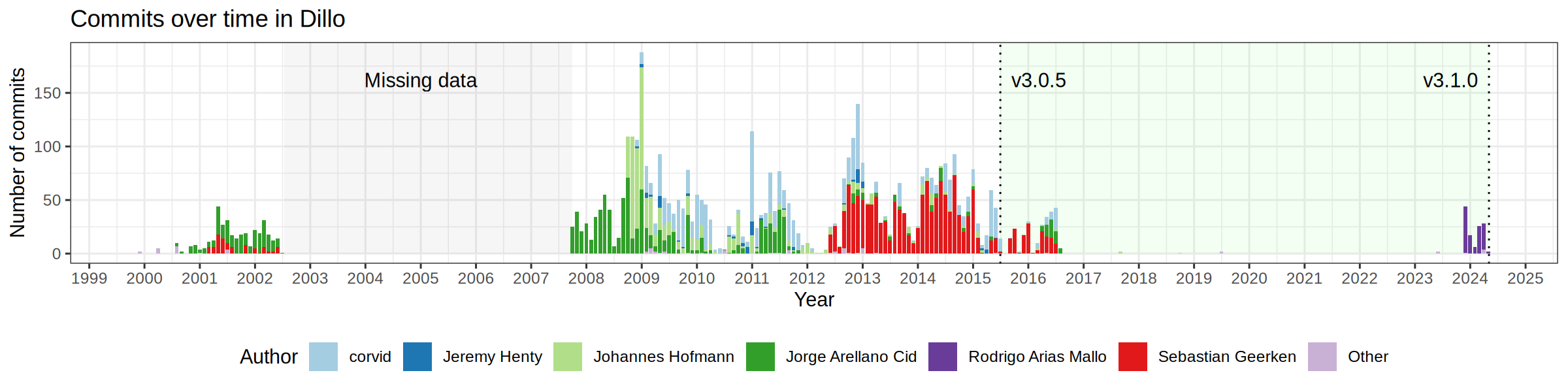
Huh, somehow I had the idea that Raph Levien wrote it. The PNG here says corvid, Jeremy Henty, Johannes Hofmann, Jorge Arellano Cid, Rodrigo Arias Mallo (which is presumably you), Sebastian Geerken, and "other".
I just used to use dillo because it was faster, cleaner, and left more RAM free for other uses. If there was a sufficiently broken site that I still wanted to bother loading, I'd fire up whatever the big browser was called back then.
Was a lifesaver to me back in the day, running my frankenstein machine pieced together from useless spares I cobbled together from the computer store I worked at briefly. Every piece of software I ran was trimmed down to the absolute minimum, and it was a time before the web was completely unusuable without an ad blocker. Fond memories of Dillo.
I'm impressed. It runs my dev blog quite well. Some of the CSS alignment is off and it doesn't load web fonts, but it looks basically the same as Chrome. Even the syntax highlighted code snippets work.
Having never used Dillo before, I just installed it and tried it. And then I found out that it does not support JavaScript at all. There aren’t many or any sites/apps that I regularly use that would work without JavaScript. That limits its usefulness.
If a website needs javascript to be usable, this is a bad website and should be avoided.
If it is a webapp, it should provide an API so you use it using your own cli/tui/desktop/mobile client, otherwise it is a bad web app and should be avoided.
I installed the latest (version 1.4) FreeDOS just now and keeping half an eye on the installer as names of installed packages flashed by I noticed Dillo. Is DOS still a supported platform or is FreeDOS shipping some old version? I hope it is the former.
Unfortunately, none of those ports made their way back to the main project. However, if there is enough interest I would be willing to merge them. I'm not very familiar with DOS/FreeDOS, so probably someone would have to help us to update the changes, but probably doable between 3.0 and 3.2.0.
I don't know if you saw that, but I asked a question in there I am still curious about. In the long time period that Dillo was largely idle, there were various forks.
Thanks for the article and for including all the references.
We now adhere to https://semver.org/ as much as we can, where each of the three version numbers has a meaning, so it would be nice to include them all. I'll mention it in the next release (and probably add it to the changelog as well).
> I wondered if you were in communication with any of those developers, and if you have managed to bring in any of their code or improvements?
I'm in contact with the Mobilized Dillo developer and we exchange some patches from time to time.
> Are you using the latest FLTK?
The change from FLTK 1.3.X to 1.4.X breaks many things in Dillo. One of my priorities is to get it fixed ASAP but it will take a while. I'll probably ship experimental support for FLTK 1.4.X under a configure flag in the next 3.3.0 release so I don't delay it for too long.
Dillo started as a fork of the Armadillo browser which was based on GTK+. It was the next version - Dillo 2 - which was ported to FLTK. The GTK+ version did not support CSS and initially did not support frames/iframes either. I submitted a patch which added support for the latter somewhere around 2003 which was never merged before the port to FLTK but which I have used for quite a while until these features became less important due to the uptake of CSS.
I just started it up and it turned out to be Dillo 3.0 from 2011. I do not know if it was using FLTK back then, but a quick search says that FLTK has been ported to DOS so that might not be an obstacle for the current developers to keep FreeDOS support if they wanted to.
Jorge originally said "Dill-O" in a video, but I almost always say "Diyo" because I'm Spanish and the word comes from the Spanish word "armadillo": https://en.wikipedia.org/wiki/Armadillo
> mandatory JavaScript everywhere, even on google.com
Note: DuckDuckGo still offers a perfectly usable JS-free search engine if you visit the website from a browser with no/disabled JS support. Almost all other major search engines now require JS to function.
Someone mentioned that you could install it using Brew. I was a little surprised how quickly it installed. Installing anything via Brew normally take a while, but apparently that's not the fault of Brew, stuff just have a large number of dependencies and a large package size.
The lack of JavaScript is an issue in terms of what sites work or even render properly, but damn everything is fast without it.
I may be imagining this, but I'm nearly certain I was running dillo on a PDA (I want to say Palm Treo) around 2001. I remember it feeling revolutionary to open up a webpage on something other than my linux desktop computer at the time. Over Wifi!
i first met Dillo pre-installed on a DamnSmall Linux CD back around 2005. i also had quite low performance PCs as others say. i browsed via Dillo till my pentium MMX laptop died in 2010 (coincidence?)
the other good browser I was happily using on old machines is Elinks. AFAIK it's also picked up again to continue its development, although it's terminal-based.
`brew install dillo` on Macs (and see [0] for other platforms)
and then `dillo` starts up a 1.1Mb executable that is so freaking, shockingly fast.
TIL I also learned that although the Google homepage renders beautifully, I need to "Turn on JavaScript to keep searching" [1]
Wow, Google Maps is even snarky-ish about it: "When you have eliminated the JavaScript, whatever remains must be an empty page." (that's what appears! for real)
Yeah, Google stopped working without JavaScript in the last year (although I believe this is a region-dependent block and may also vary by user agent string)
Yeah, I tried to reach out to Google back when they introduced the JS-wall, but they seem to have an AI chatbot acting as a filter, so I didn't spent much energy.
Later they also blocked other non-JS browsers like links or w3m, so I assume they no longer care. They used to maintain several frontends that worked in really old devices.
I don't think there is any User-Agent that works today, however you can still use the Google index via other search indexes that can fetch Google results without JS (for example Startpage still works). However, it is probably a good idea to have more options available that have their own independent index engine (for example Mojeek). Seirdy has a very good list: https://seirdy.one/posts/2021/03/10/search-engines-with-own-...
Startpage is a good recommendation! I am able to search the web using my browser with startpage. I had tried duckduckgo but have been unable to get past the captcha.
for searching in Dillo. Once in a while you may get a captcha from DDG that is far better that any other captcha I have ever seen. The captcha is easy to use and can be a bit fun :)
There's Florb, a client for Open Street Maps written in FLTK, almost like a DIllo's cousin in concept.
Pro: as light as Dillo.
Cons: You need OCaml's OMake in order to build it, but DIllo's author it's OFC aware of it and he might migrate the OMakeFile to a single Makefile.
Are there any plans to sandbox the content handling (e.g. HTML parsing and image loading) in a separate process to mitigate e.g. memory-safety issues and other security problems?
Firefox [1] and Chrome [2] use seccomp-bpf and various other Linux-specific APIs to implement their sandboxes. FreeBSD provides Capsicum [3] for this, but it's not supported by Firefox or Chrome.
Maybe Dillo could use the newer Landlock API [4] on Linux, which is being evaluated [5] for Chrome. This API seems more similar to Capsicum, so it might make it easier to support FreeBSD as well.
Yes, we did some experiments with pledge and landlock, but we need to redesign some parts to be able to properly isolate them into separate processes first.
In the short term you can disable CSS or images from the menu. You can also disable specific image decoders from the configuration with the "ignore_image_formats" option.
Hmm am I missing something? I wanted to download this either for Windows or Mac but I can't find the download link anywhere. It looks Linux only, but the title of this post says Multi-platform.
Make it easier for people to download this please. I clicked releases on the hoem page and i get a zip file with a whole bunch of stuff a file named Dillo.Desktop which double clicking tries to open in Gimp and then does nothing. On github it's the same.
Wow, this is something. I recall (decades ago, so who knows how accurate) running Dillo under Enlightenment DR17 on a low-spec Pentium (perhaps) in the old era. Glad to see it's still kicking. The computer was too slow for the rest of the software of the era but Dillo was still fast!
I was very proud that I could call our home phone line and it would boot the computer if it was off. Most pointless feature ever, but I thought I was hot shit when I was a kid getting that to work.
You know, it's been decades and all I remember is the functionality rather than the implementation. It can't have just been some built-in Wake on Ring because I knew I had to do quite a bit of work to make it function (all just a matter of putting things together not that I wrote any code).
But an amusing follow-up is that I remember going to the Red Hat offices in Raleigh for an interview for an internship and actually describing the implementation as one of the things I'd done with a computer when I was much younger. It can't have been anything impressive because it didn't land with the interviewer. Silly naïveté of a child to think that's the kind of story you tell.
{kind=link}
We are currently in the process of moving Dillo away from GitHub:
- New website (nginx): https://dillo-browser.org/
- Repositories (C, cgit): https://git.dillo-browser.org/
- Bug tracker (C, buggy): https://bug.dillo-browser.org/
They should survive HN hug.
The CI runs on git hooks and outputs the logs to the web (private for now).
All services are very simple and work without JS, so Dillo can be developed fully within Dillo itself.
During this testing period I will continue to sync the GitHub git repository, but in the future I will probably mark it as archived.
See also:
- https://fosstodon.org/@dillo/114927456382947046
- https://fosstodon.org/@dillo/115307022432139097